Simulating Elections with Spatial Voter Models
Democracy: a concept almost universally revered, underpinned by the foundational act of voting. However, interpreting voting results to make fair and representative decisions is anything but straightforward. While it’s tempting to think the option with the most votes should just triumph, reality proves more complex. Our elections are held together with a plethora of details — primaries, runoffs, ranked ballots, and more — that work together to produce reasonable outcomes.

But are these mechanisms functioning as intended? How effectively do they work, and which ones outperform others? What unintended consequences might they bear? Answering these vital questions is critical to the ongoing project of refining our democracies. Yet, answers to these questions often rely on anecdotes, oversimplification, and broad assumptions. In this article, I’ll guide you through a more robust approach to these questions — one that relies on computational modeling and simulation. (Here’s the code for the simulation.) Along the way, we’ll uncover some eye-opening consequences of our chosen election methodologies.
However, the main challenge in modeling any social phenomenon is translating the complex behaviors of humans into mathematical constructs. A model that misrepresents voters’ behaviors isn’t merely useless — it can actively mislead. We’ll encounter instances of this pitfall along our journey. Thankfully, when it comes to voter behavior, it’s possible to utilize a relatively simple, visual, and intuitive approach: spatial voter modeling.
So, join me as we embark on this investigation, exploring some critical questions surrounding voting and democracy through the lens of computational simulation with spatial voter models.
What’s so hard about voting, anyway?
Democracy is often described as “majority rule,” but what happens when there are multiple choices, and none of them can claim majority support?
Plurality voting (misleadingly termed “first past the post” or FPTP), where the candidate with the most votes wins, works well for choices between two options. When there are more than two choices, though, it has unfortunate consequences:
- Vote splitting: voters split their choices between many similar options, so no single candidate receives enough votes to stand out.
- The spoiler effect: a special case of vote splitting where even a hopeless candidate changes the result by attracting enough votes to cause a different candidate to lose.
Common wisdom suggests that the United States and other modern democracies conduct most elections with simple plurality voting. Common wisdom, though, is commonly wrong! In fact, plurality voting is very rarely used on its own. Its flaws are hard to ignore, so it’s instead propped up by a labyrinth of mechanisms and voter behaviors to compensate for them. Partisan primaries are used to coalesce political party support around a single choice to minimize vote splitting. Voters are persistently reminded not to “throw their vote away” on spoilers.
These are examples of tactical voting: voting in a way that doesn’t honestly express your preferences in order to produce an advantage for your preferred outcomes. Tactical voting means the outcome isn’t determined by majority support, but rather by cleverness and manipulation.
Alternatives to plurality voting
Given the challenges posed by plurality voting, numerous alternative systems have been proposed that aim to choose a more representative outcome. Instead of working around vote-splitting and the spoiler effect, they try a frontal assault on the whole phenomenon by changing the rules of the election itself. These often employ ranked or rated ballots, which ask voters to either rank candidates in order of preference or score candidates on a scale. By collecting more detailed information on voter preferences, they can make a choice that better reflects those preferences.
Choosing a winner from these ballots, though, is more complex than single votes, and many systems have been proposed. Instant runoff voting, or IRV, chooses a winner by eliminating candidates one at a time. It has been used in elections across the United States in Maine, Vermont, New York, Virginia, Utah, Alaska, and more. Other alternatives that are commonly advocated are range voting, STAR voting, Borda count, and many more.
In more theoretical circles, Condorcet voting is understood by most experts as the gold standard in social decision making, and it tries to choose a Condorcet winner: the candidate who would have won any head-to-head election against any other candidate. Selecting the Condorcet winner in a ranked ballot election offers huge advantages: it is the unique choice that best aligns with the principle of majority rule and expresses the unambiguous preference of voters. Crucially, though, a Condorcet winner isn’t guaranteed to exist at all. There are many Condorcet-consistent voting systems that choose a Condorcet winner if they exist or someone else if not!
It’s easy to get lost in the world of voting systems. But before we get there, I want to focus less on the specific election systems for a bit, and more on an opportunity: if we could observe any of them in action, we could dig in and see with our own eyes what the practical consequences are. To do that, we’ll want to pose some key questions that can be answered through computational modeling and simulation.
Key questions
Choosing an election system, as we’ve seen, is a delicate balance. Practical considerations and theoretical ideals are both important, but there’s a third leg to the tripod: empirical evidence. To fully understand the implications of these systems, we can conduct a numerical investigation of simulated elections.
Our exploration will center around these key questions:
- Although these proposed alternative election systems can yield different outcomes for the same voter preferences, how often do these differences actually occur? When they do, how can we describe the nature of the disagreement?
- Tactical voting — the need for it, and the effect it has when it occurs — is a critical concern in building fair voting systems. What forms does tactical voting take, and what is its practical effect when it happens?
- The chief benefits of Condorcet voting hinge upon the presence of a Condorcet winner. But how frequently do they appear, and in what types of elections might they fail to emerge? How impactful is this concern for real-world election scenarios?
- The goal of any social process should be to produce happy people. Aside from all the tactical concerns, can we say anything about which election systems actually make people happier?
Ideally, we’d delve into these questions using a vast store of real-world election data. However, such data is notoriously scarce. Uses of instant runoff voting (IRV) are on the rise, but remain somewhat uncommon. Moreover, when IRV elections do occur, comprehensive data regarding ballot distributions is not always disclosed. Real world instances of Condorcet elections and other voting systems are even more rare.
One solution lies in computational modeling and simulation, allowing us to generate an unlimited array of hypothetical election scenarios and scrutinize how various voting systems react. Though it comes with its own challenges, this methodology equips us to address the questions above by examining a multitude of different scenarios, offering valuable insights into the dynamics of voting systems.
Understanding voter behavior from simple to sophisticated models
Modeling voter behavior is critical in simulating elections, but this task is not without its challenges. As human beings, our reasons for making choices are sometimes inscrutable. Nevertheless, we can construct models to approximate the behavior of voters. It’s crucial to create effective and realistic models; otherwise, our simulations could end up unhelpful or even misleading.
Simple models: Impartial Culture (IC) and variants
The most basic model we could consider is the Impartial Culture (IC) model. In IC, each voter randomly ranks the candidates. Despite its simplicity, the IC model is generally considered unrealistic. Voters simply do not make entirely independent and unbiased decisions in this way.
More nuanced variations such as the Impartial Anonymous Culture (IAC) and even Impartial Anonymous Neutral Culture (IANC) were developed to address this flaw. These models very gently introduce dependence between the behavior of different voters. However, they continue to generate essentially equally likely outcomes.
Based on these models, the likelihood of a clear winner is low: a Condorcet winner is predicted nearly 0% of the time by IC and around 37% for IAC when the number of candidates is significant . Furthermore, they predict little agreement between different voting systems. However, we must remember that these models are based on assumptions of neutral and random voter behavior, which do not reflect actual voting patterns.
Models like IC and IAC are better suited for exploring worst-case scenarios than predicting realistic outcomes. To explore more probable outcomes, we need to adopt a different voter model.
Spatial voter models
Real world voters base their choices on factors such as political ideology, personal values, and group identification, leading to clearly discernable patterns in voting behavior. This is where spatial voter models come into play, as they can reflect these real world patterns with a bit of tuning and care.

Spatial voter models place voters and candidates in a multi-dimensional “space” of political opinion. Instead of location, the dimensions in this space are stances on various issues or alignment with political philosophies: for instance, the left-right political divide can be seen as a one-dimensional space, with left-leaning, right-leaning, and moderate voters and candidates each having their place on a continuum.
A two-dimensional example is found in the Nolan chart, an advocacy tool used widely by the Libertarian party. One axis represents a person’s stance on “personal freedom”, and the other on “economic freedom”.

Because voters and candidates are located in a geometric space, we can consider the distance and direction between them. The premise of spatial models is that voters are more likely to choose the candidates who are closest to them to them in this “space”, indicating agreement on fundamental positions.
Spatial model #1: Fixed variance uniform model
The most straightforward spatial model we can use is a fixed variance model with a uniform distribution of voters. In this model, each dimension varies by the same amount, and every candidate or voter has an equal likelihood of being at any point within the political space. This space forms a square (in two dimensions) or cube (in three dimensions) with voters dispersed uniformly throughout.

These models are inherently abstract. The importance lies not in labeling the axes according to specific issues but in the existence of variation in multiple directions. While low-dimensional models communicate more effectively, higher dimensions capture a more nuanced picture of reality. Reality is almost always infinite-dimensional, but we can only perceive finite-dimensional projections.
To illustrate, consider a model with 100 dimensions, representing a variety of issues, with 10 candidates and 100,000 voters. I’ve simulated this, and the outcome differs significantly from earlier models.
- Different voting systems demonstrate a high level of agreement; the same candidate often wins regardless of the voting system.
- A Condorcet winner appears every time.
However, these findings are unrealistic. Plurality voting is known to be unreliable with many candidates, necessitating ranked ballots, primaries, and other mechanisms. To explain that, we’ll need a more realistic model.
Spatial model #2: Decaying variance and Zipf’s law
It turns out that the very aspect we introduced for greater realism — the 100-dimensional space — is the cause of the problem. By reducing the number of dimensions, we see results more in line with expectations.
However, using too few dimensions loses the expressive power of the spatial model, leaving out certain voter preferences. I covered this in an earlier post, Geometry, Dimensions, and Elections. With the following three candidates and a one-dimensional spatial model, the model fails to account for voters who prefer both candidates A and C over B.

By adding add a second dimension, we permit the model to understand these preferences.

We’re left with a conundrum: while too few dimensions can fail to explain certain voter preferences, too many dimensions can result in unrealistic outcomes due to a lack of constraints and loss of spatial coherence. The solution is to use a high-dimensional space, but constrain the variance of the additional dimensions. In reality, not all axes of political ideology carry equal weight in determining voter decisions.
The fixed variance model doesn’t account for variable importance of dimensions, but it’s not an unusual phenomenon. With data in a high-dimensional vector space, it’s common for a few particularly significant directions of variation to account for a substantial portion of the overall variance. This principle underlies key concepts in data science, such as Principal Component Analysis.
Here, it can be captured by applying Zipf’s law, a statistical rule of thumb that suggests a pattern of diminishing returns in measurements: the second greatest measurement might be about half of the largest, then a third, and so on proportional to 1/n. Zipf’s law has been found to apply to distribution of words in a language, city populations, even the income distribution within countries. By structuring our model in line with Zipf’s law, we can ensure that the most important political issues have the most impact on voter decisions.

This model allows the incorporation of a high number of dimensions without losing spatial coherence. With this revised model, we see the differences between voting systems become evident. We’re still using a 100-dimensional model with 10 candidates and 100,000 voters, but this time applying Zipf’s law to the variances:
- Condorcet and range voting results differ from plurality results 85% of the time.
- Condorcet and range voting differ from instant runoff (IRV) about 60% of the time.
- IRV differs from plurality about 50% of the time.
These results highlight critical role of carefully adjusting our models to ensure they represent reality accurately… but our journey toward better models isn’t over yet.
Spatial model #3: The Mixture of Zipf Gaussians
This model counters the uniformity assumption. Real voters aren’t spread evenly across the political spectrum like buttered bread. Instead, they cluster according to location, personal values, cultural influences, and social groups.
These clusters can be modeled using a Gaussian, or normal distribution, where the mean represents the cluster’s center, and voters are centered around this point.

However, a single Gaussian oversimplifies by implying most voters share similar or identical views. A more accurate representation involves multiple clusters, each with its own opinions. This yields a mixture of Gaussians (MoG) model, which represents voters forming communities of interest — like political parties, religious groups, or neighborhoods — and reaching consensus within these communities rather than beyond them.
Building realistic models required carefully tuning some details:
- The number of clusters: Selecting 10 allows overlap and interaction between groups, but going beyond 10 introduces too much random noise, obscuring the distinct clusters.
- The size, location, and spread of each cluster: Groups vary in homogeneity and range, and almost always have some overlap with neighboring clusters.
- The orientation of each cluster: I slightly reshuffled the original order of dimensions before applying Zipf’s scaling law to each subpopulation, balancing the overall population dynamics with each group’s unique focus on certain issues.
The result can be termed a Mixture of Zipf Gaussian (MoZG) framework. Each specific model generated from this framework is defined by random placements and parameterizations of clusters. To look at the some of these models, I’ve sampled voters (blue dots) and candidates (goldenrod boxes), projected them from the full 100 dimensions down to two, and plotted them. You can see a couple examples here.


I’m quite fond of the generated models. They seem to capture the structure, texture, and unique character of organically developed voting populations. Voters and candidates have distinct and multi-dimensional positions, form overlapping factions with differing priorities, and even these factions have outliers. You could weave a convincing narrative about the motivations and history of each hypothetical population. These models are now ready to provide insights into the structure and dynamics of election systems within a complex and realistic setting.
Simulation and Analysis
Now that we’ve established a model for voters and preferences, let’s use it to scrutinize voting systems and glean insights into their real-world behavior. For this experiment, I’ve run numerous simulated elections using MoZG voter models described earlier, with the help of open source code I’ve made available at https://github.com/cdsmith/spatial-voting. We’ll be examining results from a thousand elections using 100 dimensions, 10 candidates, and 1,000 voters. These results are representative of a fairly wide range of parameters, though. Let’s dive in!
When and how do election results disagree?
For elections with more than two candidates, the best method for choosing a winner is still an open question. With these model voting populations at our disposal, we can take a bite at the question by asking: how often do these systems disagree, anyway? When they do, what is the nature of the disagreement?
To find out, I’ve identified winners for these thousand elections using the following methods:
- Plurality. Each voter casts a vote for the one candidate they like best.
- Instant runoff (IRV). Voters rank candidates by preference. The candidate with the fewest first place rankings us eliminated. Repeat until there’s a winner.
- Condorcet. Choose candidates who beat everyone else in head-to-head elections.
- Range voting. Each voter rates every candidate on a scale from 0 to 100, and the best average score wins.
- Approval voting. Each voter selects as many candidates as they like, and the candidate with the highest percent wins. For the initial simulation, voters are assumed to approve of any candidates nearer than average to their positions.
- STAR voting. Like range voting, but with a head-to-head runoff between the top two scoring candidates to determine the winner.
- Borda Count. Each voter ranks candidates by preference, and the candidate with highest “Borda count” (which is equivalent to the lowest average rank) wins.
The following table illustrated the frequency of agreement between these voting methods. In cases where a method does not always agree with itself, it’s due to ties, which would go away with more voters with Approval voting, but are endemic to the Condorcet method.

The Condorcet, Borda Count, Range, and STAR voting systems agree on the winner in at least 80% of cases. It is especially noteworthy that STAR and Condorcet methods give nearly identical results, agreeing in 19 out of every 20 elections. These systems form a loose consensus that can be used as a baseline for comparing the others.
On the other hand, IRV, Approval, and Plurality differ significantly, agreeing with the previous group in only 40-65% of elections. For IRV and Plurality, this is a result of their reliance on first-place rankings, meaning that they can disregard general support for moderate candidates, instead favoring candidates with strong support from specific subgroups even if they are polarizing outside their base of support. Approval voting shows the opposite bias, largely disregarding strength of support and favoring candidates who aren’t widely disliked.
This data challenges a common claim among advocates that IRV, while not always yielding the best winner as compared to other methods, is easier for voters to understand (especially compared to Condorcet voting) and often delivers satisfactory results in practice. The observed 35% disagreement between IRV and the general consensus of ranked or rated voting methods is quite significant, which argues against using IRV as to estimate this consensus in a realistic voting population.
The effect of tactical voting
Our analysis so far assumes that voters simply express their own preferences on their ballots, not considering the anticipated voting behavior of other. However, this isn’t the case in reality. Given access to sophisticated polling and analysis, voters can and do guess the candidates most likely to win, and cast their ballots to maximize the influence of their votes based on these predictions. This is called tactical voting.
I’ve also run the the same elections as above assuming that voters cast tactical ballots. These virtual voters have access to imperfect information about the likely winners, and use it to tailor their ballots. While the details depend on the voting method, this often means exaggerating their feelings for or against the most likely winners.
Firstly, let’s examine the likelihood of that tactical votes changing the result for each voting system:

Tactical voting had virtually no influence on the outcomes of Condorcet and IRV, because there is no strategy for my voters with their imperfect polling information to vote tactically in a way that benefits them; it’s simply too difficult. In contrast, tactical voting impacted the remaining voting systems to varying extents, with the greatest changes observed in Approval and Borda Count. After this shift, the agreement table for winners looks somewhat different.

For most voting methods, tactical voting is a type of prisoner’s dilemma: if everyone were to agree to vote honestly, it would result in outcomes that better represent voter preferences, whereas tactical voting chooses less representative winners. Nevertheless, the only thing worse than everyone voting tactically is everyone else voting tactically. Any individual group choosing to vote honestly while everyone else continues to vote tactically will end up significantly less happy with the results. You can especially see this trend in Borda Count and Range voting, and to a lesser extent with STAR voting.
However, Plurality and Approval voting buck this trend. In these systems, voters collectively tend to favor the results with tactical voting. Because they collect so little information about voter preferences, these methods do a poor job of choosing a representative winner in an election with many candidates. Voters are better off coordinating among themselves and then voting tactically to achieve the agreed result.
Approval voting is a more difficult case due to its inherently tactical nature. Voters must choose a satisfaction threshold for approving a candidate, a choice that’s strategic, without a definitive right answer. Previously, an “honest” approval ballot, meaning one where voters approve candidates they prefer over the average, didn’t perform well. Selecting a more tactical cutoff that differentiates between the likely winners yielded better results. However, this comes with a caveat: the outcome hinges on voters’ beliefs about likely winners. The result in the table above reflects a specific assumption about the accuracy of those beliefs. While it appears promising, the results get significantly worse if voters have more reliable information about likely winners! Therefore, relying on tactical voting to make approval voting outcomes more palatable in real-world conditions would be a gamble.
Spotlight on Condorcet winners
Earlier, I mentioned that four voting systems — Condorcet, Range, Borda Count, and STAR voting — often yield similar results. Among these, Condorcet voting showed the highest resistance to tactical voting, making it appear quite attractive. However, there’s a wrinkle in the story of Condorcet voting.
A Condorcet winner is the contender who would triumph in any head-to-head election against any other candidate. When a Condorcet winner emerges, they bring with them two compelling benefits:
- They reflect the epitome of majoritarian principle: no other candidate is preferred by a majority over them.
- Elections that select a Condorcet winner are definitively choosing the true preference of voters. No candidate can be manipulated into emerging as the Condorcet winner through any sound strategy of tactical voting.
Why not always choose the Condorcet winner, then? Surprisingly, they may not exist at all! This is Condorcet’s paradox: even a voter population with clear preferences may still lack a coherent preference as a group. Because of this, there isn’t just on Condorcet voting system. Instead, there are many Condorcet-consistent systems, which all choose the Condorcet winner if they exist, but differ in what to do otherwise. The version I’ve implemented simply declares a tie in that case, producing a worst-case analysis, but in practice some specific tie-breaking rule would be needed.
Traditionally, much time and ink (or bandwidth) has been spent on how to handle elections without a Condorcet winner. The possibility that such a winner may not exist destroys many nice theoretical guarantees about the properties of a Condorcet-consistent voting system. But with simulation data in hand, we can ask one simple question: how often does this even happen?
The answer: seldom. In my latest simulations, this situation arose in just 3% of elections. Hence, I didn’t include the whole zoo of Condorcet-consistent options, as they would have all agreed on 97% of winners, making any differences between them statistically trivial. This suggests that the possible lack of Condorcet winners is largely inconsequential in practice, allowing Condorcet voting systems to effectively deliver on their promise of choosing the most representative candidate and curbing tactical voting risks.
Keeping voters happy
Earlier, I highlighted a rough consensus among the Range, Borda Count, STAR, and Condorcet voting methods when we assume honest voting. I’ve been using this as a proxy for the ideal election outcome. This assumption was convenient, but does it actually reflect what voters want?
The question of what voters want is a subtle one. In the immediate aftermath of an election, the happiness of voters with the results will likely be tied up in the relationships between candidates, dashed hopes, and shattered expectations. We don’t have a model that can explain these feelings, but we anticipate they will fade with time. We can, however, assess the enduring satisfaction that comes from being governed by the elected candidate, after the dust has settled and focus shifts to the realities of governance.
Since spatial voter models gauge voters’ political preferences by their distance from the candidate, we can reframe the question in those terms: which candidate has the least average distance from voters? As you may surmise, I’ve simulated this ranking, too. It’s not a realistic voting method, because in reality there’s no way to directly measure this distance. However, the spatial model provides exactly answers in our simulated populations.
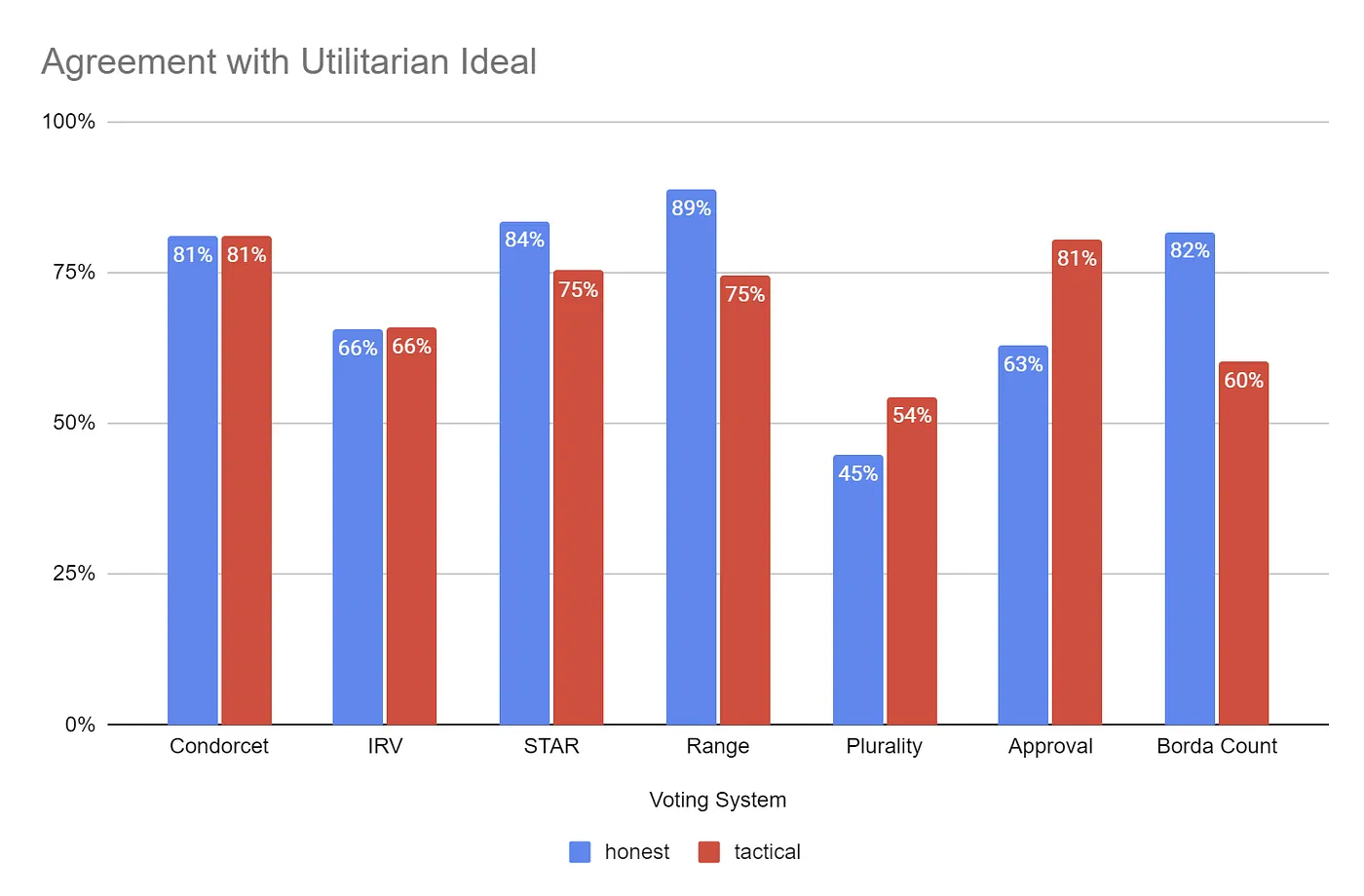
With honest voters, the top performers are familiar. In this case, Range voting aligns with the utilitarian ideal winner 89% of the time, which is not surprising since the range ballot is itself a measure of satisfaction, albeit rescaled to the candidates in the election instead of measured on some kind of universal scale. Range voting is closely followed by STAR voting, Borda Count, and Condorcet. These four systems formed our earlier consensus, validating it them as an appropriate benchmark.
Once we adjust for tactical voting, Condorcet and Approval voting take the lead under these parameters. However, recall that the results of tactical approval voting depend crucially on the amount of information available to voters. Too little, and it looks like honest approval voting, which is not so great. Too much, though, and tactical approval voting looks similar to tactical plurality voting, which is even worse. In the quest to optimize for the utilitarian ideal, STAR voting would make a more reliable runner-up to Condorcet.
Conclusion
Our exploration of spatial models and voting systems has revealed some insightful and occasionally surprising observations, and has also challenged several prevailing assumptions.
- These simulations indicate that a Condorcet voting system — which elects the candidate who would triumph in any head-to-head election with any other candidate — aligns well with the utilitarian ideal and the consensus of the best alternative systems. On top of this, Condorcet voting proves entirely resistant to tactical voting behavior. Despite theoretical concerns that a Condorcet winner might not exist in every election, we find that a Condorcet winner is absent in only 3% of simulated elections. This presents the exciting possibility that Condorcet systems could provide a pragmatic and robust way to maximize voter satisfaction in real-world elections.
- Voting systems such as Range, STAR, and Borda Count also align closely with the utilitarian consensus when voters voice their genuine preferences. However, these systems are susceptible to tactical voting. Voters who anticipate the behavior of others using polling data or other sources and adjust their votes accordingly can distort the election far away from the utilitarian ideal. After adjusting for tactical voting, STAR voting remains as a promising choice, though a bit diminished from its performance with honest voters.
- We’ve seen evidence that Plurality and Instant Runoff Voting (IRV) often produce election outcomes that differ significantly from the consensus of more utilitarian, or happiness-maximizing, voting methods. IRV, although a large improvement over naïve plurality voting, offers only a marginal advantage over the heavily tactical form of plurality voting we use in practice, guided by primaries and extensive polling data. Thus, the continued reliance on Plurality and IRV misses an opportunity to elect more representative candidates with broader appeal.
- Approval voting has perplexed our analysis. When voters cast honest ballots (whatever that means), approval voting doesn’t look attractive. When we simulate tactical votes, approval voting ranks well. However, making different assumptions about the quality of information available for tactical voting, something we cannot control in the real world, makes a huge difference in the result.
Naturally, this analysis has certain limitations. Although the voter models we investigated appear realistic and reproduce the qualitative properties we targeted more accurately than simpler models like IC and IAC, they do involve several assumptions about the distribution of voters’ political preferences and their voting behavior. Many of these assumptions lack empirical validation. Nonetheless, by employing a spatial model of voter preferences, we have managed to delve deeper into the relative advantages of various voting systems than would be possible through purely theoretical analysis.
Future work could broaden this simulation to include even more sophisticated models of voter behavior and apply these insights to analyze real-world election data. In the end, it would be immensely rewarding if this work contributes in any way to a more profound understanding of democratic processes and provides insights that can help us design and choose better and fairer ways to vote.
